正如精良的设计一样,优秀的导航也大象无形。不管是浏览好友信息,还是租赁汽车,完美的导航设计能让用户根据直觉使用应用程序,也能让用户非常容易地完成所有任务。一款应用的导航可以被设计成各种样式,但我想着重介绍6种主要的导航模式,也就是主菜单的导航模式(见图1-1)。
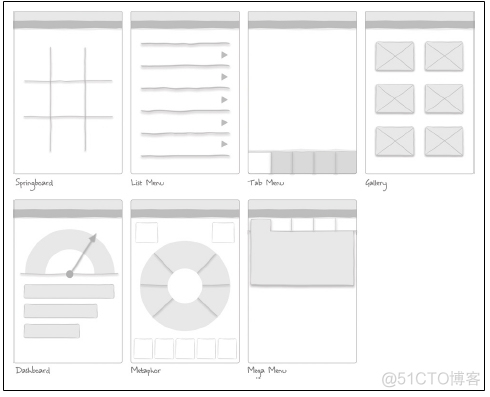
图1-1 主要导航模式
跳板式 跳板式导航对操作系统并没有特殊要求,在各种设备上都有良好表现。它有时也被称为“快速启动板”(Launchpad)。跳板式导航的特征是,登录界面中的菜单选项就是进入各个应用的起点。Facebook 应用沿用了iOS 主界面上的跳板式设计,其他应用随之跟风(见图1-2 至图1-4)。

图1-2 Facebook 的跳板式导航和Ovi Maps 应用

图1-3 Trulia 和LinkedIn 的导航设计

图1-4 Palm 手机上的NewsRoom 和Nokia 手机上的Yahoo !
个性化的跳板式导航可在显示菜单选项的同时显示用户个人资料。通常会提供自定义功能,允许用户改变跳板式导航的布局(见图1-5)

图1-5 PayPal 用户个性化的跳板式导航和Gowalla 应用的早期版本
常见的布局形式是3×3、2×3、2×2 和1×2 的网格(见图1-6)。但跳板式导航不一定非要拘泥于网格布局,你可以成比例地放大某些选项,以彰显其重要性。在iPhone的应用Masters 中,VIDEO 选项就是其他菜单选项的2 ~ 3 倍大(见图1-7)

图1-6 跳板式导航的网格布局

图1-7 Norton Mobile 的2×2 网格布局和Masters 的不规则布局
为同等重要的内容项使用网格布局,为相比之下更为重要的内容项使用不规则布局形式。视情况使用个性化设置和自定义选项。
列表菜单式 列表菜单式导航与跳板式导航的共同点在于,每个菜单项都是进入应用各项功能的入口点。这种导航有很多种变化形式,包括个性化列表菜单(Personalized List Menu)、分组列表(Grouped List)和增强列表(Enhanced List)等。增强列表是在简单的列表菜单之上增加搜索、浏览或过滤之类的功能后形成的(见图1-8 至图1-11)。

图1-8 列表菜单:Valspar Paint 和Kayak 应用

图1-9 列表菜单:Palm 手机上的RadioTime 和Cozi 应用

图1-10 个性化列表:Blackboard 和Zoho CRM 应用

图1-11 增强列表:Amazon MP3 应用;分组列表:Stratus 应用
列表菜单很适合用来显示较长或拥有次级文字内容的标题。使用列表菜单的应用要在所有次级屏幕内提供一个选项,用来返回菜单列表。通常的做法是在标题栏上显示一个带有列表图标或“菜单”字样的按钮。
选项卡式
选项卡式导航在不同的操作系统上有不同表现,对于选项卡的定位和设计,不同操作系统有不同的规则(见图1-12)。如果要为你的应用选择这种导航模式,就要为不同的操作系统专门定义选项卡的位置。

图1-12 不同操作系统内选项卡的位置
iOS、WebOS 和BlackBerry 系统都把选项卡放在了屏幕底端,这样用户就可以用拇指进行操作(见图1-13 和图1-14)。

图1-13 位于屏幕底部的选项卡:Jamie Oliver Recipes 和Molome 应用

图1-14 位于屏幕底部的选项卡:BlackBerry 系统的应用World 和WorldMate
屏幕底部水平滚动的选项卡是个非常不错的设计,如图1-15 中的Starbucks 和Blue Mobile 应用,它可以在同一屏内提供更多的操作选项。

图1-15 位于屏幕底部的滚动选项卡:Starbucks 和Blue Mobile 应用
Android、Symbian 和Windows 系统都把选项卡定位在屏幕的顶端,这种形式看上去很眼熟,因为它模仿了标准的网站导航模式。Nokia 和Windows 都在屏幕顶端设计了可滚动的选项卡,用户移动选项卡后能看到更多的菜单项(见图1-16 和图1-17)。

图1-16 位于屏幕顶端的滚动选项卡:Harvest TimeTractor 应用和Nokia 上的Fring 应用

图1-17 位于屏幕顶端的选项卡:Foursquare 和HitPost 应用
为已选择的菜单项设置不同的视觉效果,用户就能清晰地知道自己选择了哪一项。使用易于识别或带有标签的图标。
陈列馆式
陈列馆式的设计通过在平面上显示各个内容项来实现导航,主要用来显示一些文章、菜谱、照片、产品等,可以布局成轮盘、网格或用幻灯片演示(见图1-18 至图1-20)。

图1-18 BBC 和PULSE 应用

图1-19 Flickr 应用和Palm 手机上的PictureIt 应用
有时,对这些内容进行分组更易于用户浏览。Dwell 利用侧边选项卡把陈列馆式导航里的内容组织成了可供用户管理的内容块。

图1-20 Dwell 应用
陈列馆式导航能很好地应用于用户需要经常浏览,频繁更新的内容。
仪表式
仪表式导航提供了一种度量关键绩效指标(Key Performance Indicators,KPI)是否达到要求的方法。经过设计以后,每一项量度都可以显示出额外的信息。这种主要的导航模式对于商业应用、分析工具以及销售和市场应用非常有用(见图1-21)。

图1-21 Mint 和Ego 应用中的仪表式导航
不要使用过多的仪表式导航。你需要开展研究才能决定应该对哪些关键量度采用仪表式导航。
隐喻式
这种导航的特点是用页面模仿应用的隐喻对象。这种导航主要用于游戏,但在帮助导航 人们组织事物(如日记、书籍、红酒等),并对其进行分类的应用中也能看到(见图1-22 至图1-25)。

图1-22 Awesome Note 应用

图1-23 Cellar 应用

图1-24 DoItTomorrow 和TripJournal 应用

图1-25 Aldiko Book Reader 应用
一定要谨慎地使用隐喻式导航,蹩脚的模仿很可能造成10.1 节出现的反模式(anti-Pattern)。
超级菜单式
移动设备上的超级菜单式导航与网站所用的超级菜单导航类似,它在一个较大的覆盖面板上分组显示已定义好格式的菜单选项。RipCurl 网站就利用超级菜单显示服饰的次级类别(见图1-26)。

图1-26 RipCurlShop.com
WebOS 系统版本的Facebook 利用超级菜单来精简导航,避免了跳板式导航中过多的选项。Walmart 在它们的Android 应用中也采用了超级菜单式(见图1-27)。
在选择导航模式之前,首先要确定信息架构。如果要导航的对象仅仅是应用中少数主要内容,就可以使用选项卡之类的导航模式。

图1-27 WebOS 系统下的Facebook 和Android 系统下的Walmart
本文摘自《移动应用UI设计模式》
